En los años ochenta el antiguo lenguaje COBOL era el producto estrella para desarrollar aplicaciones de gestión... pero era pesado en el proceso de la programación. En esa misma época había nacido un nuevo gestor de base de datos llamado dBASE creado por una empresa llamada Ashton-Tate, y había logrado estandarizarse dentro del mundo PC.
En el año 1990 los ordenadores de 8 bits basados en el Zilog Z80 comenzaban a perder mercado en favor del mundo de la arquitectura creada por IBM para el PC... comenzó el camino de la reducción de precios de unos ordenadores IBM PC y compatibles considerados inasequibles para la informática personal. Era el momento de explorar nuevos lenguajes de programación más completos que el BASIC, y también era el momento de acceder al mundo de la programación de aplicaciones de gestión... un mundo nuevo que comenzó a abrirse a los escalones empresariales más bajos y a los domicilios particulares en aquellos años.
En los años ochenta el antiguo lenguaje COBOL era el producto estrella para desarrollar aplicaciones de gestión... pero era pesado en el proceso de la programación. En esa misma época había nacido un nuevo gestor de base de datos llamado dBASE creado por una empresa llamada Ashton-Tate, y había logrado estandarizarse dentro del mundo PC; el producto dBASE incluyó, en versiones posteriores, un novedoso lenguaje de programación soportado por un intérprete de comandos... el mismo utilizado para gestionar las bases de datos creadas y almacenadas en unos famosos ficheros de extensión «DBF». En el año 1986 nació la versión dBASE III Plus, la más famosa y utilizada de toda la serie, y con ella muchos programadores se aventuraron a crear pequeños programas para gestionar datos.
La programación en dBASE III Plus solo permitía una discreta programación dependiente de la ejecución bajo su propio intérprete, pero una empresa llamada Nantucket Corporation decidió crear en 1985 un compilador para generar ejecutables de aquellos programas desarrollados en dBASE; la empresa americana aprovechó el momento para incluir una extensa librería de nuevas funciones no existentes en el gestor de bases de datos... aquel compilador fue bautizado con el nombre de Clipper, abriendo la puerta a un nuevo concepto llamado xBase que era un conjunto de herramientas para dBASE creadas por terceras empresas ajenas a Ashton-Tate... entonces se hicieron famosas algunas extensiones de archivos: DBF para las bases de datos, DBT para almacenar los campos «memorandum», NDX para crear los índices de búsqueda, FRM para los informes, LBL para las etiquetas...
El compilador Clipper creó un nuevo mundo destinado al desarrollo de increíbles aplicaciones de gestión compiladas y «linkadas», sin dependencia de intérprete alguno. Aunque existieron versiones más antiguas, y más modernas también, concretamente las versiones dBASE III Plus y Clipper Summer'87 revolucionaron el mundo de la programación de aplicaciones de gestión dentro del mundo PC a finales de los años ochenta y primeros años noventa.
...era necesario tener en cuenta que toda la potencia para el desarrollo de aplicaciones se encontraba dentro del Clipper...
El primer paso a dar al acceder a la programación en Clipper era conocer el manejo de la gestión de las bases de datos dentro de dBASE III Plus, crear las tablas, los comandos para insertar, editar, y borrar registros... o más bien marcar registros para ser borrados definitivamente con PACK o recuperarlos con RECALL... era necesario manejar con soltura el intérprete de dBASE III Plus, lugar donde era necesario crear las bases de datos y gestionar los datos de forma manual. También disponía de algunos comandos estilo SQL como SELECT.
Una vez dominado el dBASE III Plus era el momento de aprender la primera norma, la más básica, todos los comandos podían ser reducidos a las 4 primeras letras, ya que no existía ninguna repetición de nombre de comando a partir del tercer carácter. Por ello el comando DELETE, se podía utilizar como DELE, o el comando RECALL como RECA. Así se ahorraba espacio en el código fuente. Posteriormente, era necesario tener en cuenta que toda la potencia para el desarrollo de aplicaciones se encontraba dentro del Clipper, así que era necesario aprender como compilar para crear el fichero objeto, terminando por «linkar» para obtener el ejecutable.
Toda la programación de Clipper se desarrollaba en el interior de ficheros de texto de extensión PRG, necesitando un editor de texto -el más usado en aquellos años fue el Sidekick por ser un editor residente en memoria, con la gran ventaja que aportó aquello en un sistema operativo monotarea como era el MS-DOS-. Después se abría un mundo de posibilidades, y un estilo estético propio en modo texto que siempre identificó unívocamente a las aplicaciones de Clipper; las pantallas se creaban mediante @ SAY, y @ GET, y un espectacular @ PROMPT terminado por un MENU TO permitía crear maravillosos menús de opciones con una barra de selección, algo inexistente en la programación en dBASE III Plus y que únicamente se podía lograr con Clipper.
En el modo texto se podían crear aplicaciones realmente buenas en el apartado gráfico, dando una apariencia de profesionalidad.
Al crear pantallas era necesario dominar la tabla de códigos ASCII dentro de la extensión para símbolos gráficos con la idea de utilizar los marcos dobles y marcos sencillos que nos permitían, a mano, encuadrar los diferentes apartados de cada pantalla; de tanto usar aquellos códigos ASCII se llegaban a memorizar todos los códigos... las cuatro esquinas duplicadas para la línea doble y sencilla, el marco horizontal y el vertical... y todo se combinaba haciendo un REPLICATE de fondo usando, por ejemplo, los caracteres ASCII 176, 177, ó 178 que aportaban una apariencia de tapiz de fondo de las pantallas. En el modo texto se podían crear aplicaciones realmente buenas en el apartado gráfico, dando una apariencia de profesionalidad.
Posteriormente tocaba desarrollar el grueso de la aplicación, un programa llamaba a otro mediante el comando DO, y retornaba al llamante mediante RETURN; los controles de errores no existían, y la depuración se basaba en colocar @ SAY en los puntos estratégicos para ver el valor de las variables en ejecución. A las bases de datos DBF de dBASE se accedía mediante el comando USE, se añadía un registro en blanco mediante APPEND BLANK, y se rellenaban los datos con REPLACE. Los campos se mostraban y se editaban mediante @ SAY ... GET, pudiendo establecer el tipo de datos y el formato mediante PICTURE, y validar mediante VALID. El comando ZAP, el más temido de todos, era el que borraba de golpe toda una base de datos sin marca previa y confirmación posterior.
Las variables de memoria se podían almacenar en disco...
Las operaciones numéricas con la base de datos se podían realizar mediante SUM, COUNT, o AVERAGE, y los datos eran exportables a ficheros externos al DBF mediante COPY TO, normalmente se utilizaba el formato SDF para exportar al exterior. Con INDEX se creaban los índices para búsqueda, y con SEEK se ejecutaba una búsqueda mediante el índice activo. Si existía más de un índice, se utilizaba SET ORDER para activar el deseado. Con el comando LOCATE se podía buscar un registro sin índice pero... ¡cuidado!... la búsqueda podía retardar la ejecución de la aplicación. Las variables de memoria se podían almacenar en disco, en ficheros de extensión MEM, mediante el comando SAVE TO, y eran recuperadas mediante el comando RESTORE TO... lo más parecido a un fichero INI de Visual Basic 6.0 o al «app.config» de Visual Studio .Net.
En realidad, la programación era totalmente secuencial, y todo lo estructurada que el programador tuviera paciencia de «tabular» a mano en el editor de texto. No era una programación complicada, y un desarrollo de calidad para una aplicación de gestión se podía ejecutar en muy poco tiempo. Quizás el mayor problema era la depuración de errores, que siempre era ejecutada de forma manual. Para los procesos más comunes y habituales se solían reutilizar funciones creadas para una aplicación para incorporarlas a otra nueva en desarrollo; cuando se había finalizado el primer desarrollo de una aplicación de gestión, incorporaba el estilo de programación propio de cada uno y servía de base para las siguientes aplicaciones a desarrollar, sobre todo en el apartado de visualización y gestión de bases de datos. Por tanto era habitual utilizar como base un proyecto anterior en cada nuevo programa a crear.
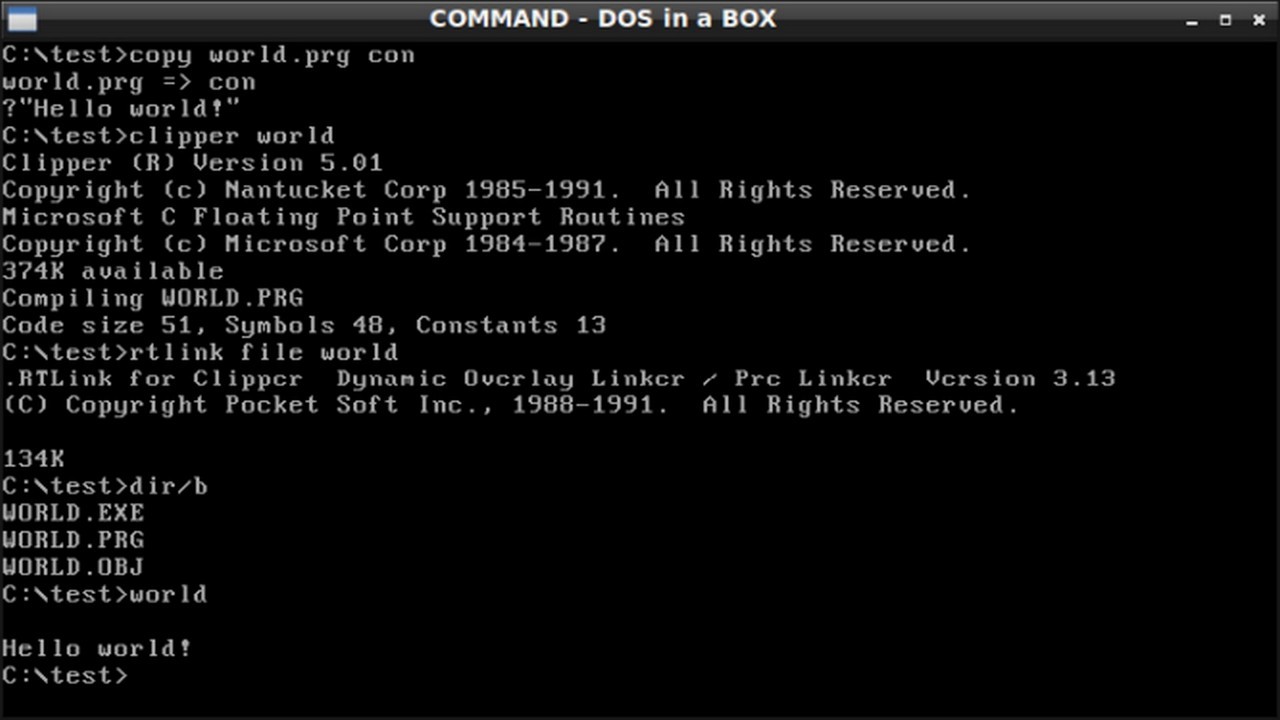
El proceso de compilado creaba un fichero objeto de extensión OBJ inteligible para el sistema operativo.
Una vez que el archivo DBF de base de datos estaba creado, y todos los archivos PRG de programación desarrollados, era el momento de compilar y «linkar». El proceso de compilado creaba un fichero objeto de extensión OBJ inteligible para el sistema operativo. Para ello se utilizaba el archivo Clipper.exe que era el compilador que, partiendo de los ficheros PRG, creaba los ficheros OBJ. Después de obtener los ficheros objeto, se requería el linkado para unir al fichero objeto las rutinas más básicas que requería el software para ser ejecutado en MS-DOS, y para ello se utilizaba el famoso comando PLINK86 FI.
El linkado, en realidad, era un proceso común para el sistema operativo MS-DOS, ya que el fichero OBJ era el mismo independientemente del compilador utilizado (RM-COBOL, BASIC, Clipper, etcétera), y lo que todo programador en Clipper aprendió rápido fue que el PLINK86 era muy lento. Todos los desarrolladores de aplicaciones en Clipper sustituían el «linker» entregado con el Clipper por otro más potente... unos utilizaban el RTLINK, yo utilizaba el TLINK, «linker» muy rápido y potente incorporado en el Turbo C. Con el compilado y «linkado» se obtenía el ansiado fichero EXE que permitía ejecutar dentro del MS-DOS la aplicación desarrollada.
¿El compilado y «linkado» se ejecutaba al final de desarrollo? Pues no. En realidad, para cada prueba de ejecución durante el desarrollo, para cada cambio, para cada pantalla nueva, para cada función nueva añadida, para poder ejecutar el proceso de prueba de la aplicación, era necesario compilar y «linkar» y obtener un fichero EXE. Por lo tanto se solía crear un proceso BATCH o proceso por lotes en un fichero de extensión BAT donde se ejecutaba todo el proceso de compilado y «linkado» de forma automática pasando, a modo de parámetro, el fichero PRG principal; dentro del BAT se ejecutaba en un tiempo récord todo el proceso de creación de un EXE.
Aquellas pantallas en modo texto diseñadas mediante REPLICATE, SAY, GET, y PROMPT disponían de su encanto y su dosis de ingenio.
El desarrollo de aplicaciones de gestión en el año 1990 era extremadamente flexible y rápida usando el dBASE III Plus y Clipper, pero la programación era más aburrida y contaba con menos posibilidades si la comparamos a los lenguajes de programación visuales modernos basados en objetos, procedimientos, funciones, clases, y eventos, todo ello asociado a conceptos como sobrecarga, herencia, polimorfismo, etcétera. Pero desarrollar una aplicación Clipper requería trabajar la informática de otra «forma» perdida en el olvido actualmente; las nuevas generaciones no conocen aquella informática. Y aquellas pantallas en modo texto diseñadas mediante REPLICATE, SAY, GET, y PROMPT disponían de su encanto y su dosis de ingenio.
En 1994, y a las puertas del mundo gráfico en los sistemas operativos, desarrollé a los 19 años de edad mi primera aplicación de gestión que vendí y tuvo éxito, fue programada íntegramente en Clipper para la gestión completa de un videoclub -negocio de gran éxito en aquellos años-. Aquella aplicación contó con todo el espíritu que he intentado plasmar a lo largo de este artículo y, además, fue el trabajo que me llevó a pasar de informático «amateur» a profesional ¡Como olvidar aquella programación en Clipper!



















El compilador Clipper abrió la puerta a un nuevo concepto llamado xBase.